

What the hell is ray tracing, and what the hell is a blockmap?
Ray Tracing is the coding technique used to figure out what can be ‘seen’ from object to object. If you’ve ever played a first-person shooter, you’ve experienced a ray-tracer, because that’s how the game determines what parts of the map you can see and what parts you can’t. Objects in the foreground prevent you from seeing what’s behind them.
Ray Tracing is simply tracing a ray. A Ray is a geometry concept, it’s a line that starts from a point and travels in a direction until it hits something. In strict geometry, rays don’t hit things, but in our code they sure do.
Oh, and this would more accurately be called a ‘line-segment’ as opposed to a ‘ray’, because these have a definite end point. But since the code can be generalized to rays and ray sounds a lot cooler, I’m using ray.
Pandemonium uses ray tracing to figure out if an enemy can see you, the player. If the enemy can, they will chase you and trigger a battle. So it makes sense that they wouldn’t be able to see you through walls unless they have x-ray vision.
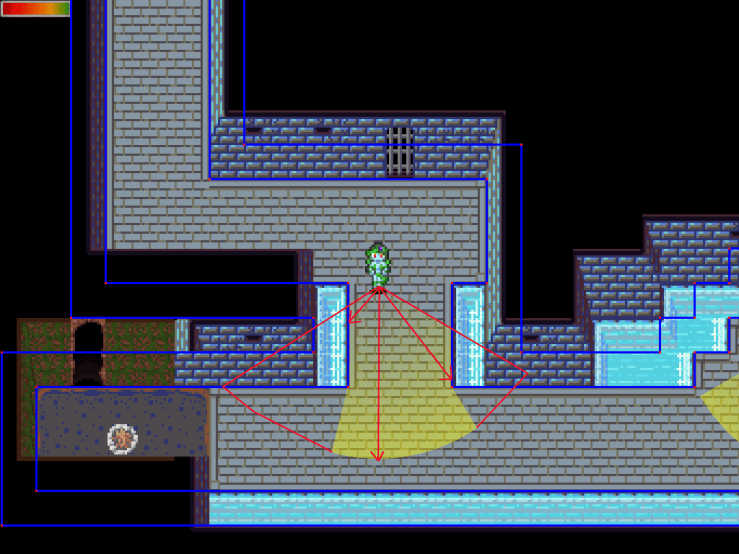
In this image, I have enabled Mei’s visibility cone to simplify things. The yellow area is what she can ‘see’ while the red polygon represents what she’d be able to see if the walls weren’t in the way. The red arrows are rays, and they collide with the blue lines which represent collisions.
Pandemonium does not simulate verticality. So, enemies cannot see over the water, because they can’t chase over the water. It’s one of those design decisions that makes a lot of sense from a gameplay perspective but not from a reality perspective.
Okay, so what’s a Blockmap?
Raytracing is computationally expensive. In order to see if a given ray impacts a line, we need to run the line-intercept function. It looks like this.
I sincerely hoped you enjoyed that link.
The line-intercept function must be run for every line in the entire map against every ray you want to trace. For Pandemonium, every viewcone is about 120 rays. You can customize the accuracy in the options menu if it causes slowdown. 120 is just a good middleground number that looks nice without being too intensive.
So, if there are 600 lines in a map, and 120 rays per viewcone, then that’s 72,000 calls of the line-intercept function for every entity with a viewcone. 600 is not an unreasonable number of lines, and some of the larger maps have thousands of lines. This gets expensive, quickly.
It sure would be handy if we had a way to only check a ray against the lines it could reasonably impact, as opposed to every line on the map. The rays are short and always focused around the same spot, so an optimization would mean instead of checking against 600 lines, we check against 10.
This optimization is called a Blockmap.
What does a Blockmap look like? How does it work?
Blockmaps simply sort the lines on the map by where they are.
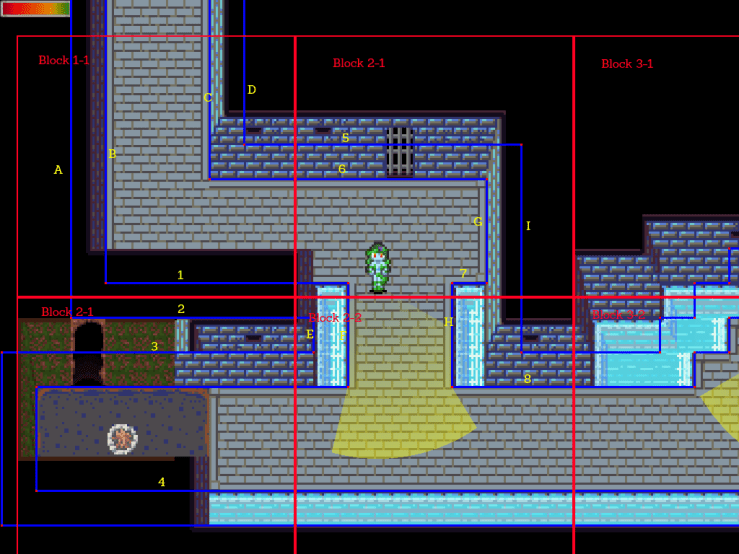
Here we can see a crude overlay which shows what a blockmap might look like. The vertical lines are labelled ABC etc, while horizontal lines are 123 etc.
Block 1-1 contains lines A, B, C, D, 1, 5, and 6. Any line which touches the block at all is considered to be within it. This can be determined with a simple line-intercept function call, and only needs to be determined once. That is, I can compile this data into the map and it never needs to change. Block 1-1 always has the same set of lines in it.
There are 16 vertical lines and 16 horizontal lines visible in this image, give or take the edges. That’s a total of 32 lines. If I had a ray that started and ended in Block 1-1, then I would only need to check 7 lines. That means the Blockmap speeds up raytracing by about 500%. Five times faster for a simple bucketing algorithm, pretty impressive!
If a ray starts in one block and ends in another block, all you have to do is check all the blocks it hits, which can again be determined via either a line-intercept function or a point comparison. Simply check which block the start point and end points are in, and check those blocks as well as any blocks between them. For a short ray like the one in this screenshot, a ray can be in as many as 3 blocks, which is still considerably faster than checking every single line on the map. The algorithm becomes faster the smaller the blocks are, up to the point where the blocks are so small that the algorithm spends too much time figuring out which blocks the ray touches and not enough checking line impacts. It’s up to the coder to figure out the optimal size, but in Pandemonium it’s about 3-4 tiles squared since the majority of collisions in the game are big square right-angles.
Bonus Optimization: Duplicate Line Check
When a blockmap gets really small, the same lines start to appear in many blocks. It’s theoretically possible for a line to be contained in dozens of blocks, though that doesn’t happen very often in Pandemonium. When iterating across the blockmaps, checking the same line twice is just a waste of speed. What do we do?
The blocks contain references to the lines, which are stored in a single master list. To prevent duplication, we can use a unique ID system.
Every time a ray begins a trace, increment a variable, called mRayPulse, by 1. Every line in the map likewise has a variable, mLastRayPulse, indicating the last pulse they were queried by. When a ray checks a line, set the line’s mLastRayPulse variable to mRayPulse. If the ray goes to check a line, and the line’s mLastRayPulse variable is already equal to mRayPulse, it was already checked and we can ignore it. Thus we avoid all duplicate line checks.
We can also optimize the algorithm a bit by shortening the ray after each impact. Finding an impact is not enough, we need to find the shortest impact, otherwise entities would still be able to sometimes see through walls. Each time the ray impacts a line, we shorten the ray. If a ray going from Block 3-3 to Block 1-1 gets hit in Block 2-2, there’s no need to continue checking Block 1-1 since it has already hit something in between. This doesn’t save much processor time but is certainly worth mentioning.
Can we optimize this more?
Yes! However, it probably isn’t necessary in this case. Blockmaps with a duplication-proof pulse checker are ideal for short rays, such as the kind used in Pandemonium. Rays that are very long, however, are a different species altogether and won’t work with a blockmap.
For very long rays, you need a tree sorting method. If you’ve ever played Doom, Quake, or Half-Life, you’ve played a game that uses one such method: Binary Space Partitioning. This is where all the lines in the level is split into two (hence the term binary) and the two halves of lines are then further split down recursively until all the lines are isolated. The more advanced methods, Quadtree and Octree, do this same technique but use a different splitter to break space into four or eight parts instead of two. The basic principle is the same, though.
A BSP has the advantage of being fast for an arbitrary set of lines and line lengths, while also not taking up much RAM. Blockmaps are very fast for short lines and take up a fairly large amount of RAM relative to their contents, but for long lines they tend to check way too many extra lines.
I will probably do a post on binary space partitioning in the future but for now, this post is long enough and got its point across.
And for all those of you who don’t care about blockmaps but made it to the end of the post anyway: Congratulations!
